Dinner is Served
Afzal Jasani ·
A few weeks ago I was with my team in SF at a conference. We originally had dinner plans at a pretty standard American restaurant but I had other plans and quickly pulled an audible to get us a reservation for sushi. Last minute changes aren’t ideal but neither is a mediocre meal after working a conference booth all day. Plus who doesn’t love sushi?
My wife and I have done sushi omakase for every celebration for the past 10 years. I know my way around the menu without even looking at it. Most inexperienced sushi lovers go straight for the O-toro but there’s so much more out there. So naturally I told everyone I would be ordering for the table. I’ve consistently done this with friends, family, and work colleagues. 100% of the time people are willing to outsource their agency in this specific situation to enjoy a meal.
I have a strongly held opinion about how we break bread: family style, every time.
The case for optionality
But why? On one hand it reduces the risk of ordering solo and your hawaiian ribeye tasting like garbage. On the other hand it magnifies the memory of “omg that caviar wagyu bite was the single best bite I’ve had all year”. That moment stays with us. I always say for a first visit, taste everything. You can always order more later. But that only works if we do family style.
Standardizing on one LLM is the same as everyone ordering their own entree. You might be optimizing for the safe pick instead of the best outcome. I’ve talked to hundreds of companies who started their AI journey by picking one provider say OpenAI, Anthropic, or Gemini. When standardizing on one provider you’re making a bet based on what you know today and what you need today. It’s the age old story of “no one gets fired for buying and implementing salesforce” except that’s kind of changing. By the time I talk to these companies they’re ready to “graduate” to utilizing more than just one model-family and one modality. New use cases are showing up every day. It often looks like this:
- Start off with OpenAI enterprise and deploy licenses to a select few teams.
- Monitor usage across the initial cohort which shows up-and-to-the-right trends.
- Give access to additional teams.
- New use cases like image generation, transcription, and creative writing emerge.
- Find out that OpenAI doesn’t have the best models for your use and you need Gemini.
- Go to Gemini or any other provider to set up access and now observability, governance, and provisioning are broken.
The current pattern I’m seeing today looks like cost pressure but it’s deeper than that. Companies have blown through their annual budgets and it’s only June. There’s a strong desire to reduce token usage and I get it. If you accidentally use Opus 4.8 you might run through your daily budget and then you have no other options left. Close your laptop and go for a walk.
While list price didn’t change on Opus 4.7 several people wrote about the “tokenizer tax”. This was a silent change made by Anthropic which had almost a 35% increase in input tokens. That’s a meaningful change. Newer more proficient models are increasing in price as well. Anthropic released Fable which is priced at $10/M input tokens and $50/M output tokens. And it goes higher: OpenAI’s GPT-5.5 Pro lands at $30/M input tokens and $180/M output tokens. Use with caution!
Cost pressure is a forcing mechanism which can lead to either better or worse outcomes. From my reference point, I’m optimistic it’s leading to some better outcomes. I’m also lucky enough to enable these outcomes. This was a common theme during my days working in data infra. So many conversations revolved around compute costs and how much teams were spending on their data warehouse. But this focuses too much on the explicit costs versus the implicit costs. The most strategic leaders flip this conversation on its head. I would often hear “I’m already spending $1M a year on compute costs so I don’t care about reducing that by 30%. Instead, what’s more valuable is if my team of 40 analysts which costs me $7M a year is more productive. I need speed and efficiency when it comes to developer tools”.
Routing is a first class citizen
Before we dive into this next section, a quick note on what OpenRouter actually is. OpenRouter is the canonical marketplace for accessing AI. We make inference just work. We remove all the overhead around picking a provider, or picking a model, and understanding things: latency, price, TPS, model benchmarks, etc.
So now you can access hundreds of LLMs in one place through OpenRouter in a clean standardized API spec. How incredible that this exists? And all this sounds great almost like you can have your cake AND eat it but what do people actually do in reality?
Luckily I was able to pull some data around this. It’s also divine timing that today the team released our analytics API!
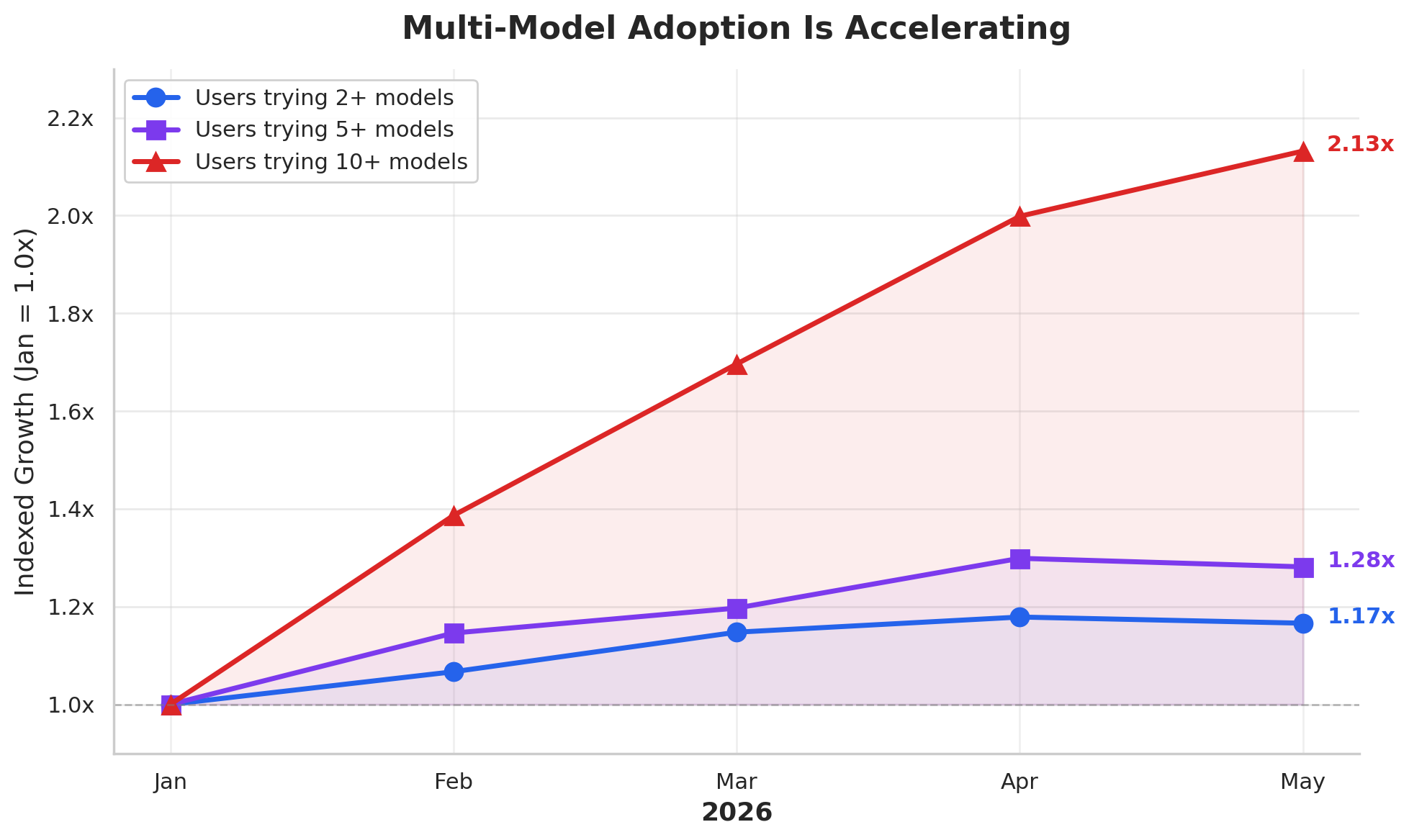
Multi-model adoption was a hypothesis we have always had but we can clearly see growth trends alongside this story. This makes sense and is expected but it obscures the fact that most people could just be trying the newest version of each model. For example, Anthropic has released Opus 4.6, Opus 4.7, and Opus 4.8 all within the graph’s timeline. So what would be more interesting is how users adopt across model families.
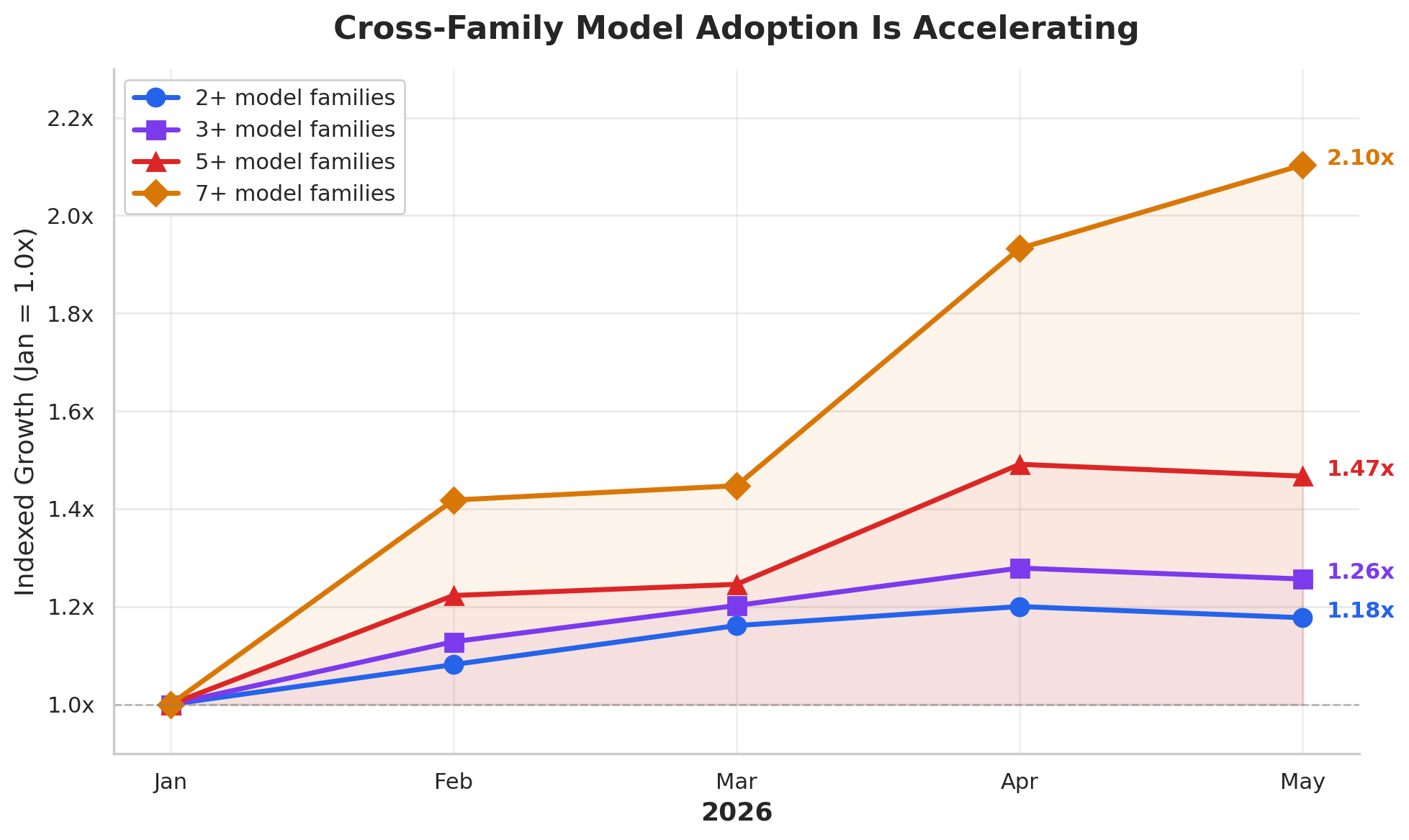
Now here we can capture the real growth around users actively spreading inference across model families. This paints a more realistic picture of what continuously graduating looks like. Let’s layer in one more data point around model releases as well.
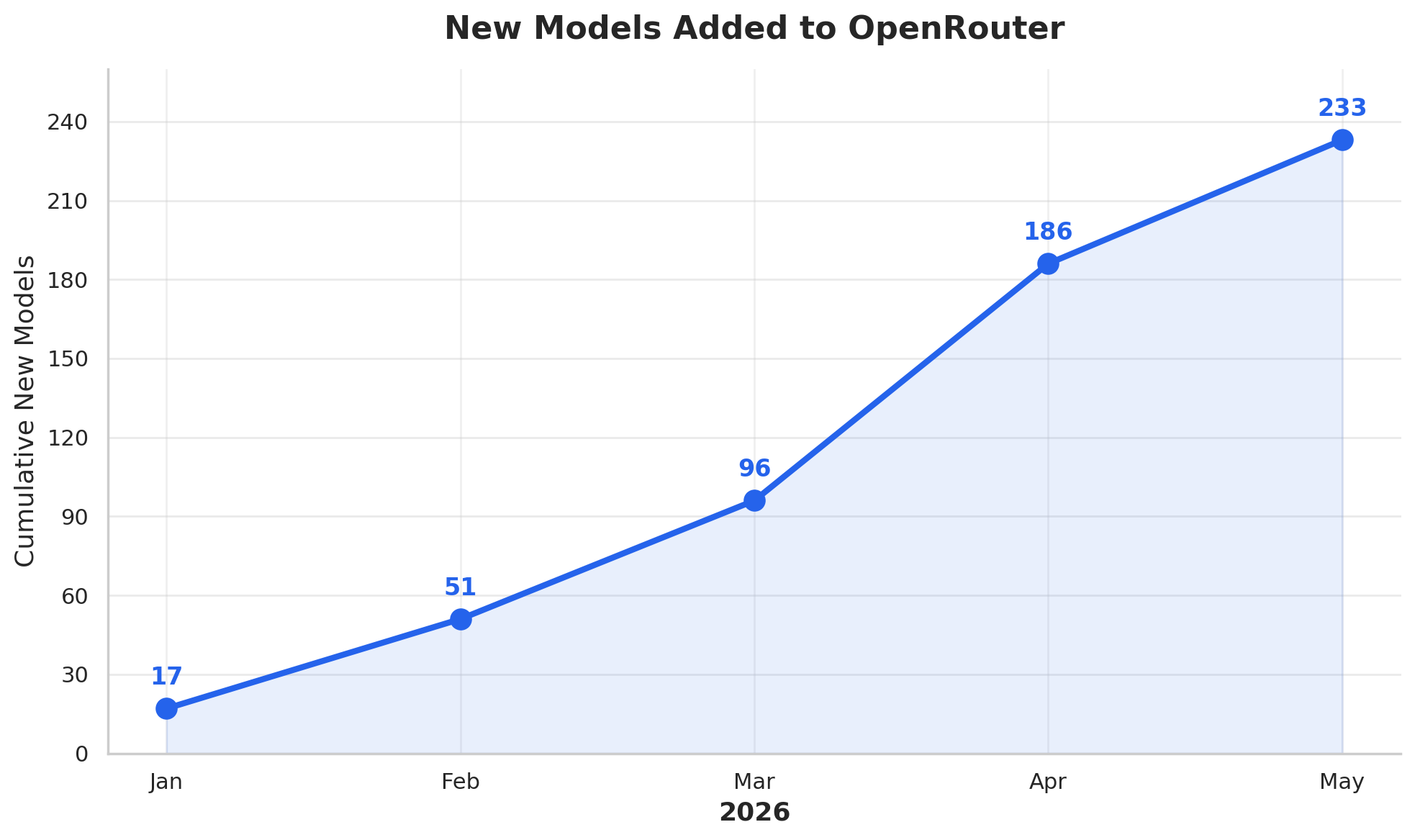
This is a cumulative chart since release schedules aren’t always consistent. But we can see one big outlier from March to April where we had 90 new model releases. That’s huge! So many more options to pick from at an increasing velocity.
That can also be a little stressful. It’s like going to a restaurant and the menu has 225 items (one of my favorite restaurants). Even with family style you can’t try them all. We obviously thought about this and don’t want our users to have to know the difference between every single model. So we built out things like auto-router and pareto-router to make it easier to pick which model to use.
All this ties back to the cost pressure I mentioned earlier. Companies are actually utilizing OpenRouter in an interesting way. They are able to bring their average weighted cost per token down over time. How is this possible? Well if you route specific workloads to specific model providers and models based on your required outcomes then you can take advantage of say Deepseek v4 flash which only costs around $0.10/M tokens on input and $0.20/M tokens on output.
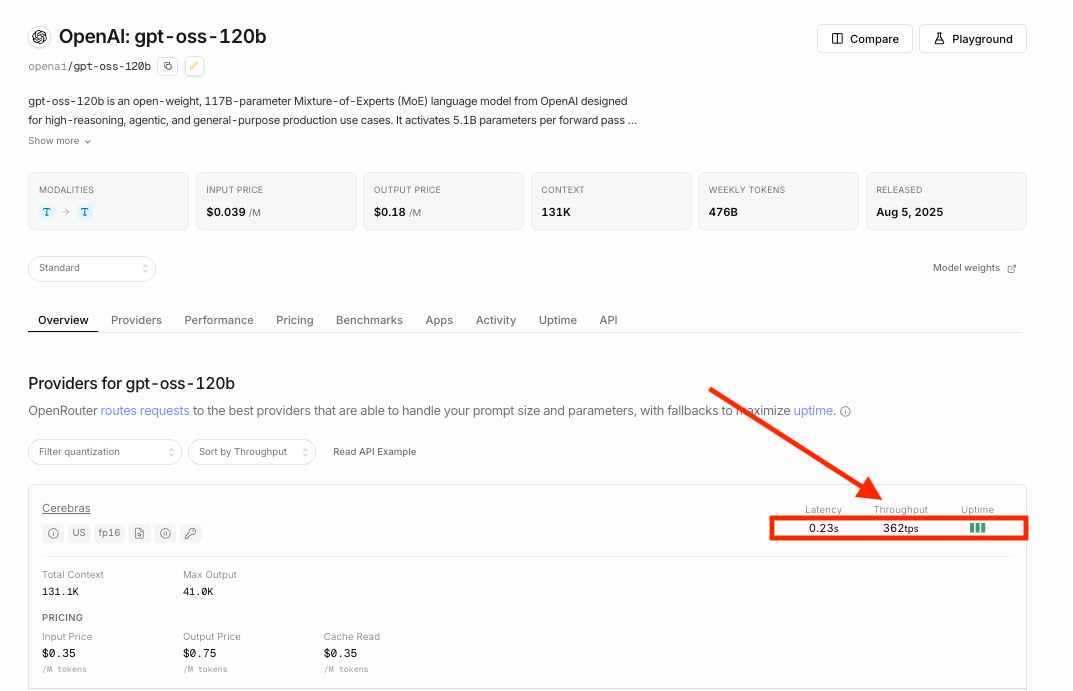
Take this one step further by utilizing a model provider like Cerebras which has some of the best throughput and now you’re the maestro like Bradley Cooper except we’re doing the heavy lifting for you.
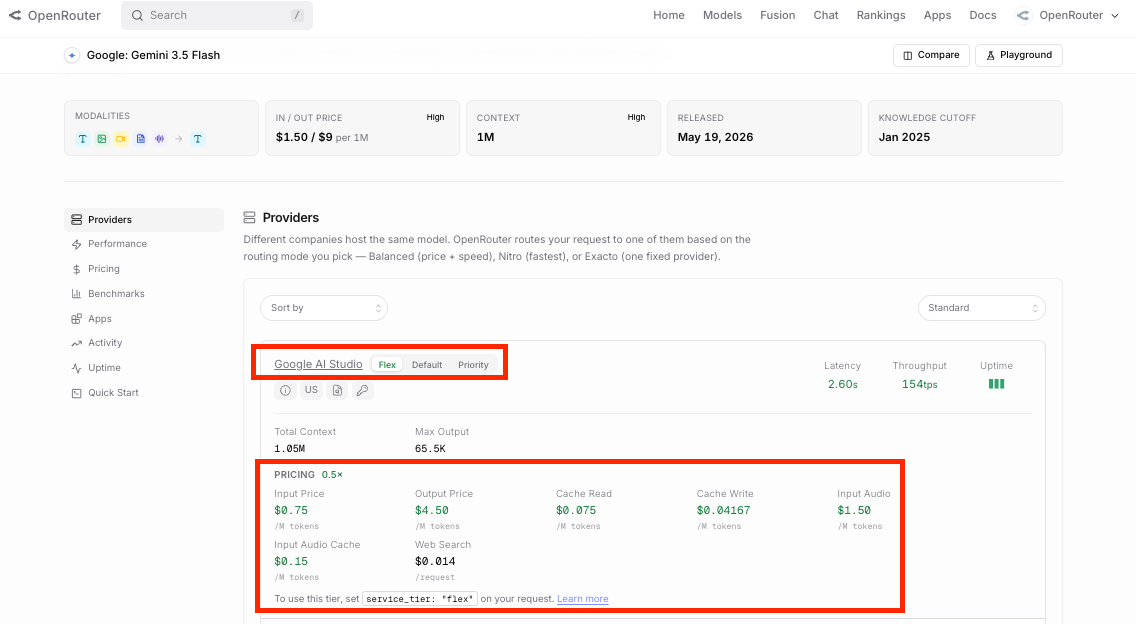
Or you route some of your traffic to flex priority tier on Gemini models to take advantage of 50% off. Again the choice is yours.
We have some exciting stuff around model intelligence that we will be sharing soon. Overall, the theme is still the same: we make inference just work.
Semper ad meliora
It feels like the tailwinds that were driving AI adoption are moving towards AI optimization. We understand that the amount of money we are spending on AI inference isn’t going to decrease by any meaningful magnitude, so what’s the next best alternative? It’s bringing the average weighted cost per token down. Organizations are becoming more intentional with democratizing usage across teams while reducing risk when it comes to governance. This really only happens if you’re not vendor locked into a single provider. When you choose to use different models for different use cases you gain leverage at each turn. You finally get to sit at the dinner table and eat as you please, family style.